
Big Data File Formats
Four ways to put bytes on disk, three of them are mistakes

The file format wars are over. Parquet won. You can stop reading.
Fine, don’t — because I keep watching people who “know” Parquet won use it in ways that throw away the whole reason it won. And because the argument didn’t actually end. It moved one level up the stack, to where half of you are now quietly unsure whether Iceberg is a file format. (It’s not. We’ll get there.)
I wrote the first version of this post years ago, when this was still a live fight — real blog wars, real benchmarks, people with strong opinions about ORC. It needs an update. So here’s what these formats are, why they behave the way they do, and what changed.
One number first, to set the stakes. I once watched a one-line change — gzipped CSV to Parquet with zstd — cut a team’s S3 bill by 70% and drop query times by an order of magnitude. Nobody got promoted for it. Storage formats are plumbing and nobody thanks the plumber, but pick wrong and you pay for it on every query you ever run. A format decides three things for you:
how much space your data eats,
how fast you write it,
how fast you read it back.
You don’t get all three.
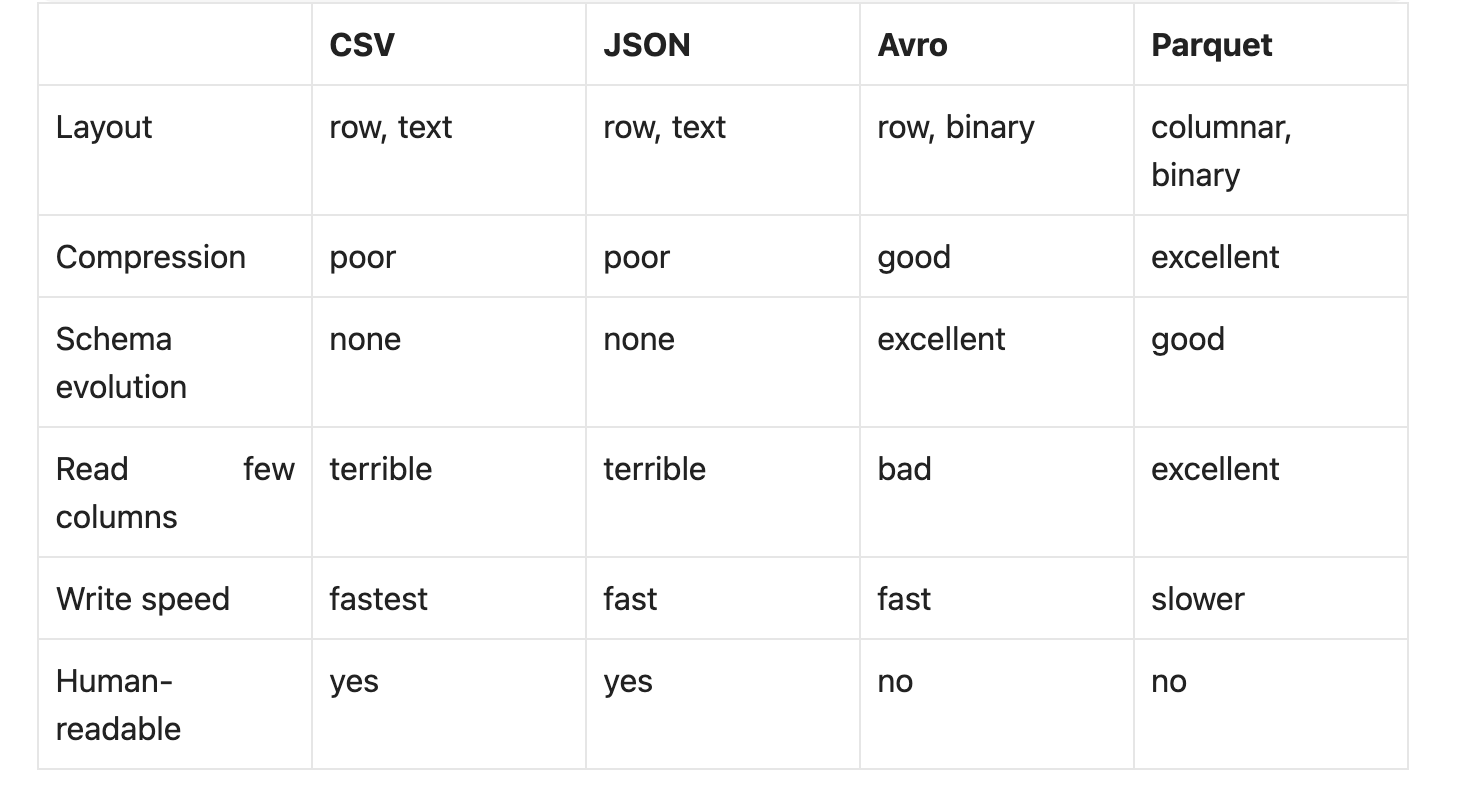
CSV
CSV will outlive us all. (c)

It’s plain text, every system can produce it, every system can read it, and when something breaks you can open the file and look at it with your eyes. That’s the whole appeal. For shoving a few thousand rows between two systems that share nothing else, CSV is fine.
For anything else it’s a nightmare.
CSV has no types — everything is a string until something downstream bets on what it means. And “bets” is the right word: Spark’s schema inference reads your data and guesses. I lost half a day once to a column of zip codes that inference decided were integers, dropped the leading zeros, and quietly broke a join three steps later. No error, no warning — just wrong numbers that three teams trusted for a week.
# gambling
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# engineering
df = spark.read.csv("data.csv", header=True, schema=explicit_schema)💡
inferSchemaisn’t free. It makes Spark read the whole file twice — one full pass to work out the types, another to actually load the data. On a big CSV that’s double the I/O before you’ve done anything useful. Pass an explicit schema and the first pass disappears.
There’s no real standard either. Commas, semicolons, tabs, quotes inside quotes, newlines inside fields, a dozen escaping conventions that all disagree with each other. “CSV” isn’t a format, it’s a family of formats that happen to share a file extension. And because it’s row-based text, an analytical query has to read and parse every byte even when you wanted one column out of fifty.
The one thing CSV does well is write fast — there’s nothing to encode. Which is exactly why it keeps turning up where it shouldn’t. It’s the path of least resistance, and least resistance is how most bad data decisions get made.
JSON
JSON does what CSV can’t — nested structures, arrays, types that mostly survive the round trip. It’s the native language of REST APIs and event streams, and as a format for moving data over a wire, it earned its spot. As a format for storing data, it’s ridiculous.
Every row drags the full set of keys along with it. Store a billion events and you’ve written the string "user_id": a billion times. Compression hides some of that, but you’re still parsing text, still scanning whole rows, still working without indexes or statistics. If you’re stuck with JSON, at least use JSONL — one object per line — so Spark (or whatever else) can split the file and read it in parallel.
💡 This is the whole reason JSONL exists. A regular JSON file is one big array —
[ {...}, {...}, ... ]— and you can’t split it, because a parser has to read the opening bracket and everything after it as a single document. One core, whole file, same trap as.csv.gz. JSONL drops the array and puts one object per line, so every newline is a clean split point and the cluster can finally parallelize. Same data, one structural change, night-and-day read performance.
JSON shows up at the edge because that’s what the service upstream emits. Fine. It should die at the edge. Land it, parse it, write Parquet. When raw JSON travels three hops into your warehouse, someone is paying to parse the same text over and over, and that someone is you.
Avro
Avro is a row format someone actually sat down and designed, instead of one we inherited from spreadsheets. Binary, compact, splittable, and it carries its own schema — schema in JSON, data in binary, any reader can decode the file without knowing anything in advance.
Its best trick is schema evolution. Producer adds a field, old consumers keep working. Consumer expects a field with a default, old files still read fine. Backward and forward compatibility, with rules that actually get enforced instead of just agreed to. That’s why Avro runs the Kafka world — schema registry plus Avro is still the standard handshake between services that change on their own schedules.
What Avro isn’t is an analytics format. It’s row-based, so reading two columns out of a hundred means reading all hundred off disk. Great for ingestion and messaging, where you consume the whole row anyway. Wrong tool the second someone points a SQL engine at it.
Parquet
Parquet flipped the layout: instead of storing rows together, it stores columns together. That one decision cascades into everything that makes it dominant.
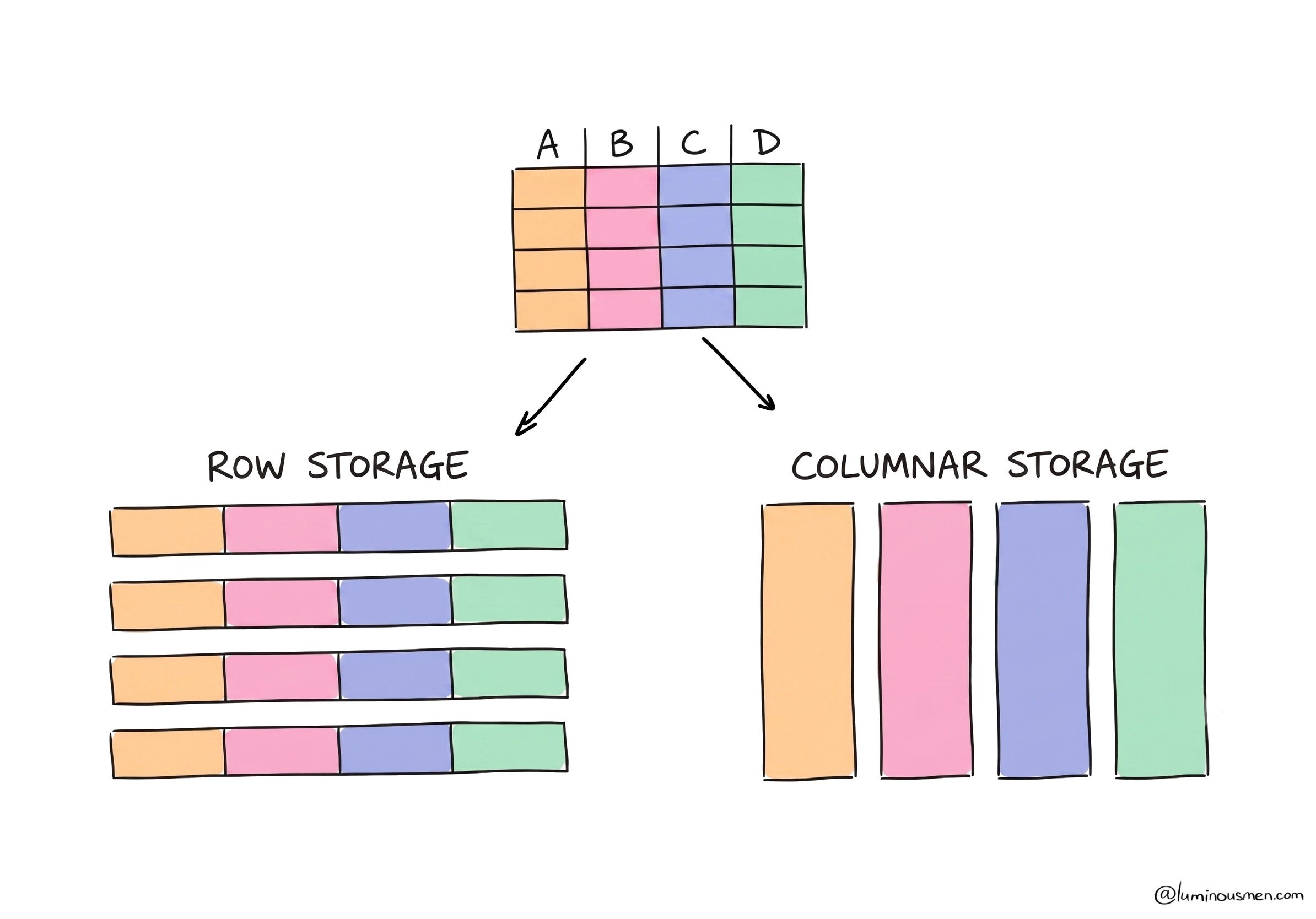
Columns compress beautifully because similar values sit next to each other — a column of timestamps, a column of country codes, long runs of repeated or sorted values. Encodings like dictionary and run-length get applied per column, then a general-purpose codec on top. Text formats can’t come close.
💡 High-cardinality columns quietly wreck your compression. Parquet leans hard on dictionary encoding — store each distinct value once, reference it by a small integer. Fantastic for country codes, status flags, anything repetitive. Feed it a column of UUIDs, URLs, or free-text and the dictionary grows bigger than the data, so Parquet gives up and falls back to plain encoding. The file balloons and nobody knows why. When a Parquet file comes out three times larger than you expected, go find the high-cardinality string column — it’s almost always that.
Column layout also means projection pushdown: SELECT user_id, amount reads two columns off disk and ignores the other ninety-eight. And Parquet files carry metadata — min/max statistics per row group — which enables predicate pushdown: a filter like date = '2026-06-30' lets the reader skip entire chunks of the file without decompressing them, because the metadata already says the value can’t be there.
# parquet reads only what the query needs
df = spark.read.parquet("s3://bucket/events/")
df.filter(df.event_date == "2026-06-30").select("user_id", "amount")
# two columns read, non-matching row groups skipped entirely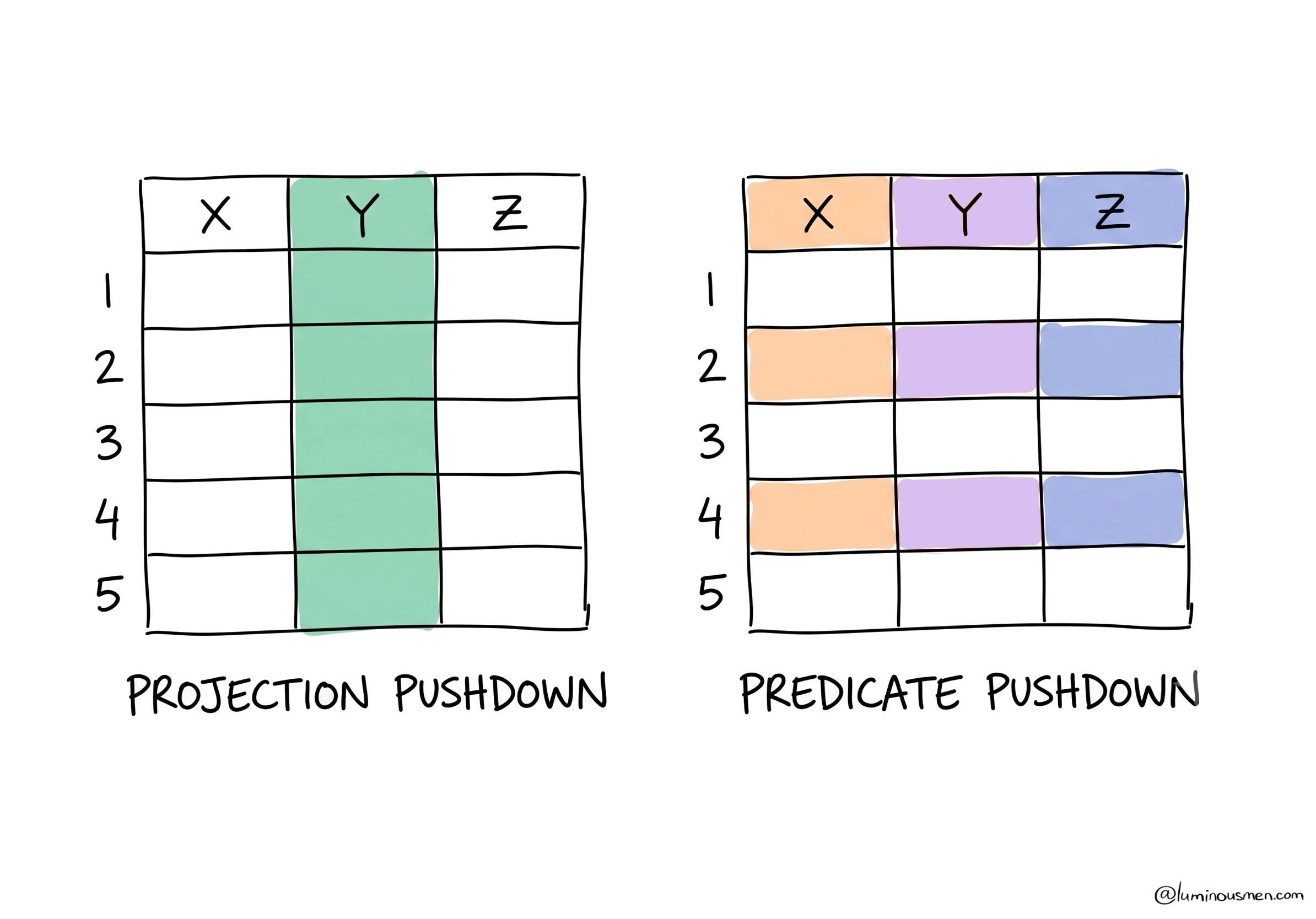
💡 Pushdown only works if your data cooperates. Min/max stats let Spark skip a row group only when values are clustered. Never sorted on
date? Then nearly every row group spans the full range — min is the earliest, max is the latest, everywhere — and nothing gets skipped. You scan the whole file and still call it “predicate pushdown”. Sort or partition on the columns you filter by, or it’s a feature you pay for and never use. (More on getting this wrong: How Not to Partition Data in S3)
EDIT: Two updates since the original post.
First, compression: I recommended snappy back then, and snappy was the right answer in 2019. In 2026, use zstd. It compresses noticeably better at comparable read speed, every engine supports it, and at cloud storage prices the gap between codecs is real money. Snappy is no longer the default you should reach for.
Second, ORC. The original debate was Parquet vs ORC, and ORC is a genuinely good format — arguably better metadata in some respects. But it lost the ecosystem game. It hangs around in older Hive setups; everywhere else, the tooling, the engines, and the new table formats all standardized on Parquet. Format wars aren’t won by benchmarks. They’re won by ecosystems. If you want proof that still holds in 2026, look at Vortex — a newer columnar format that beats Parquet on nearly every axis (faster scans, far faster random access, faster writes, same compression) and now sits under the Linux Foundation. On paper it’s the better format. In practice almost nobody runs it, because almost nothing reads it yet — the same trap that buried ORC, one decade later.
The trade-offs Parquet accepts: writes are slower (encoding and statistics aren’t free), files are immutable (no appending to an existing file — you write new files), and it’s binary, so you can’t just open it and look. For analytical storage, you take that deal every time.
💡 Small files will undo everything above. Pruning works at the row-group level, and every file carries footer metadata Spark has to open and parse before it reads a single value. Having ten thousand 2 MB Parquet files and you spend more time opening files than reading data — the columnar advantage is gone. Aim for files in the hundreds-of-MB range and compact the rest; this is half of why table formats run background compaction at all.
The original post’s advice still holds: row formats when you consume whole rows (ingestion, messaging), columnar when you query subsets of columns (basically all analytics). Avro at the front door, Parquet in the warehouse. That mental model survived the decade.
What changed
Here’s the part that didn’t exist when I wrote the original, and it’s where I watch engineers get confused in 2026.
The argument today isn’t Parquet vs Avro. It’s Iceberg vs Delta Lake vs Hudi — the table formats that turn a directory of files into a proper lakehouse. And people talk about these like they’re file formats. They are NOT, and underneath every single one of them sits plain old Parquet.
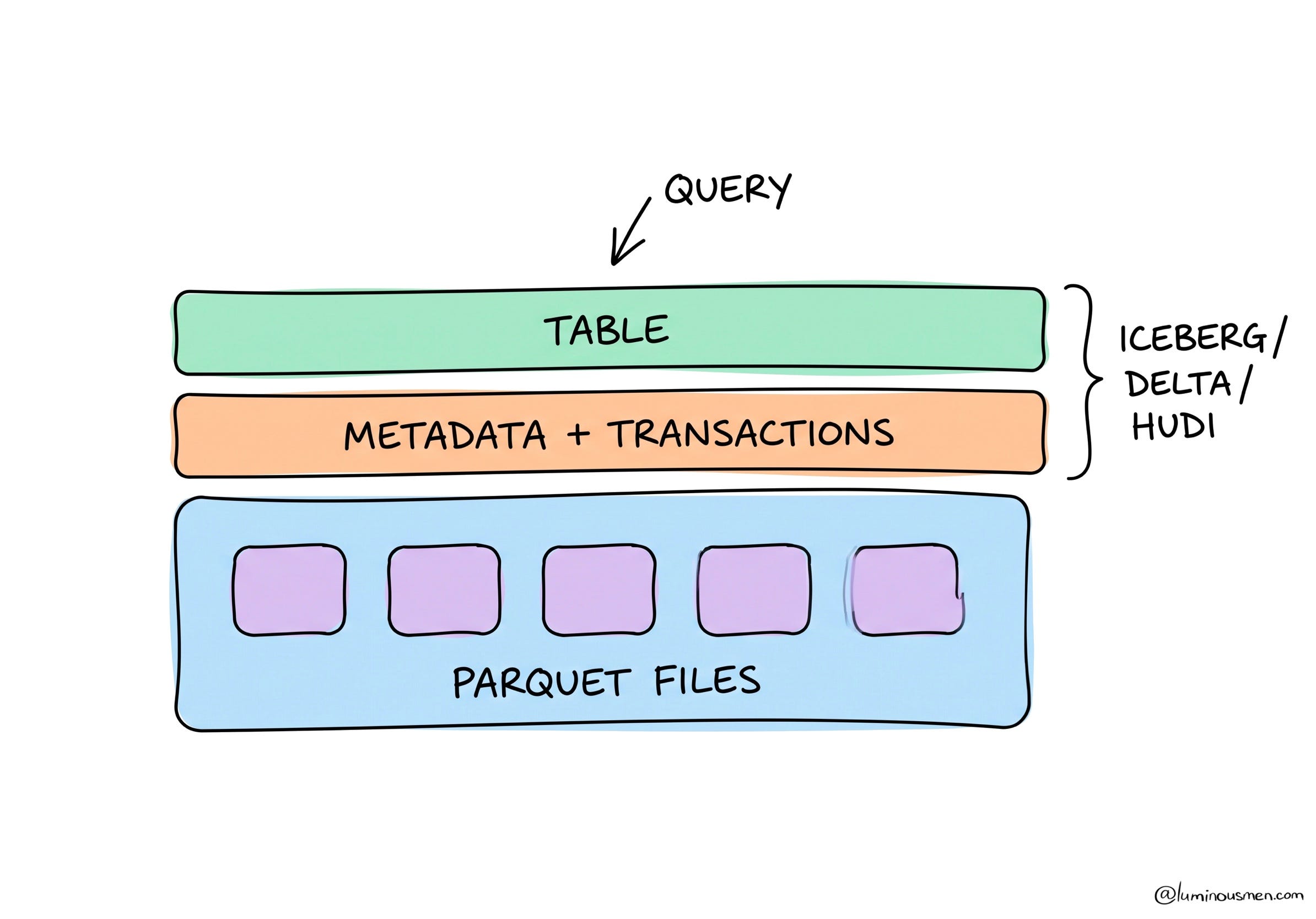
A file format answers “how are bytes arranged inside one file”. A table format answers “which files make up this table right now” — and from that you get ACID transactions, schema evolution at table level, time travel, safe concurrent writers, partition evolution. All the things raw Parquet-files-in-a-directory famously can’t do. Anyone who’s had two jobs write to the same S3 prefix and produce a half-visible mess knows exactly which problem table formats exist to solve — along with keeping all those small files from rotting your read performance.
So when someone says “we’re migrating from Parquet to Iceberg”, that’s a category error — like saying you’re migrating from bricks to architecture. You’re not replacing Parquet. You’re adding a metadata and transaction layer that manages your Parquet files. Everything in this post about why Parquet reads fast still applies inside an Iceberg or Delta table; the table format just adds another layer of file pruning and bookkeeping on top.
The file format question is settled. The table format question is where the actual decisions live now — that one deserves its own post.
The ML asterisk
One more thing the original couldn’t have predicted. ML workloads broke the old assumptions.
Analytics wants column scans, which is the one thing Parquet was built to do. Training and serving want something else: shuffle this dataset, fetch rows 10,000 through 20,000, grab the embedding for this specific item right now. Random row access. And Parquet is bad at random row access — it was never built for point lookups, and stuffing vector embeddings into Parquet columns gets awkward fast.
That gap is why formats like Lance exist, built for fast random access and vector search while keeping the columnar wins. It’s early and the space is still moving, so I won’t pretend to call a winner. For classic analytics, Parquet is safe. For ML-native storage, the question just reopened — watch it instead of assuming the old answers still cover you.
To Wrap It Up
If you skimmed everything above, here’s the operating manual. Data enters your system as whatever the source emits — JSON from APIs, Avro from Kafka, CSV from that one vendor who will never change. That is fine — you don’t control the front door. But at the next step convert everything you store for analytics to Parquet with zstd. If multiple writers or schema churn are bugging you, put a table format on top — that’s an architecture decision, not a file format one.
And never, under any circumstances, let CSV become the interface between two systems you both control. You own both ends. Pick a real format.
The formats are boring now. That’s a good thing — boring means settled, and settled means you can spend your arguments on something that still matters.
What’s the worst format decision you’ve inherited? Mine involved a multi-terabyte “data lake” of gzipped CSVs with no headers. I still think about whoever built it.
Additional Materials
Apache Parquet documentation — the file format internals
Apache Avro specification — schema evolution rules
Apache Iceberg — where the table format conversation starts
Lance — the ML-native columnar format
Vortex — the technically-ahead Parquet challenger that can’t crack the ecosystem