


Why Parquet Is the Go-To Format for Data Engineers
With more practical lessons to help you with the data engineering journey


This post is a bit of a tag team. I’ve teamed up with
, the mind behind one of the most underrated newsletters in tech. If you’re not subscribed yet — fix that. Vu dives deep into modern Data Engineering, sharing practical insights on how big companies actually build things.So here we are. Vu condensed and reworked his piece, and I, Kirill Bobrov, am here to throw in some practical context, field notes, and rough edges from the trenches.
What follows is a deep look into the internals of Parquet — not just how it works, but how to make it work better. For anyone serious about making their data systems faster, leaner, and a little less mysterious.
Let’s go.
Intro
My previous Parquet article received a lot of attention, and I’m very proud of the hard work I put into it. However, when I re-read the article this morning, I felt it still missed something.
This week, I have the chance to collaborate with Kirill Bobrov, the senior data engineer at Spotify, the seasonal blogger, and the author of Grokking Concurrency, to bring more Parquet knowledge and experience to our readers.
You will read my condensed version of the previous Parquet article, plus practical insights and experiences from Kirill.
Overview
The structure of your data can determine how efficiently it can be stored and accessed.
The row-wise formats store data as records, one after another. This format works well when accessing entire records frequently. However, it can be inefficient when dealing with analytics, where you often only need specific columns from a large dataset.
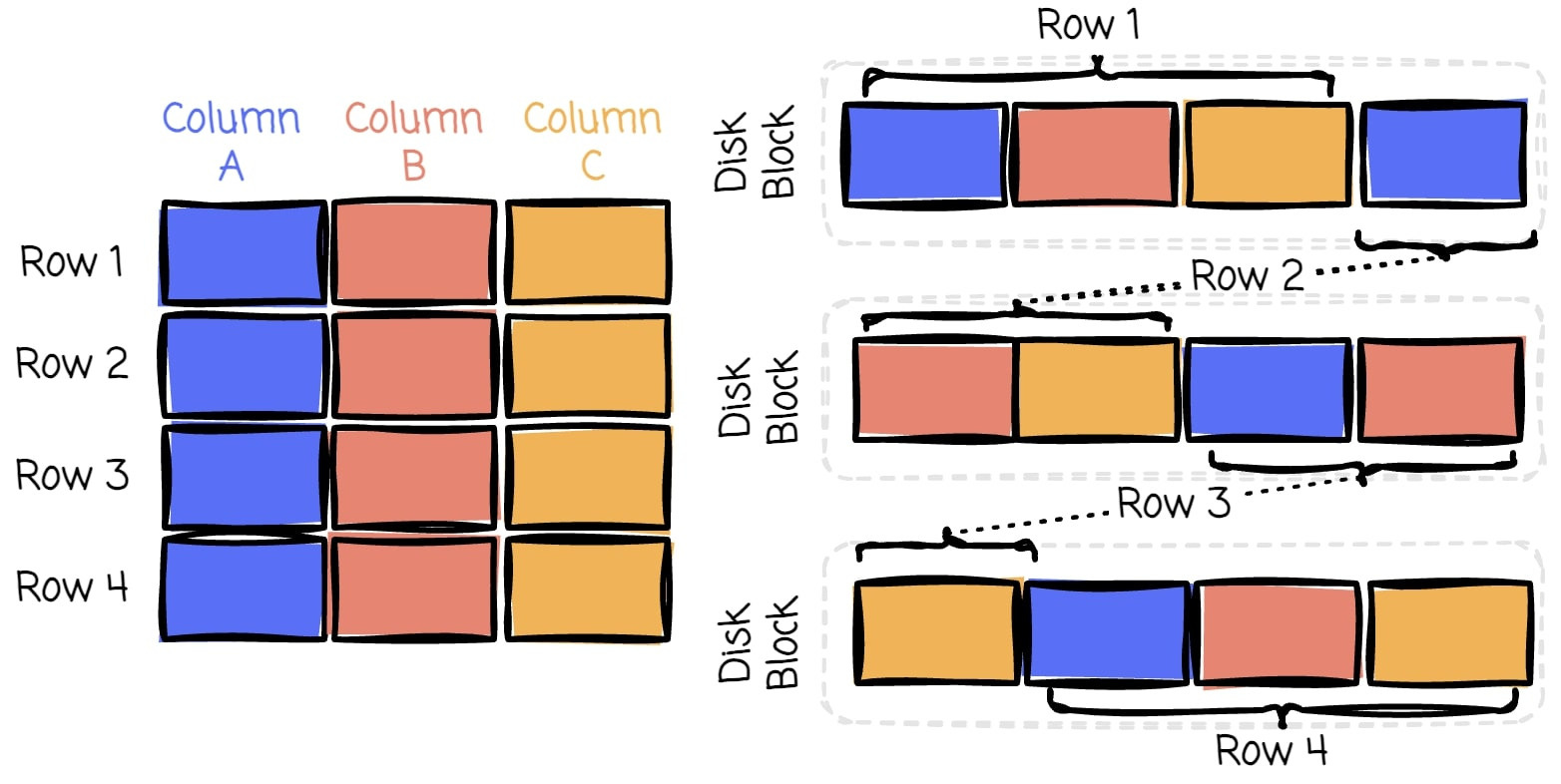
Imagine a table with 50 columns and millions of rows. If you’re only interested in analyzing 3 of those columns, a row-wise format would still require you to read all 50 columns for each row.
Columnar formats address this issue by storing data in columns instead of rows. This means that when you need specific columns, you can read only the columnsdata you need, significantly reducing the amount of data scanned.
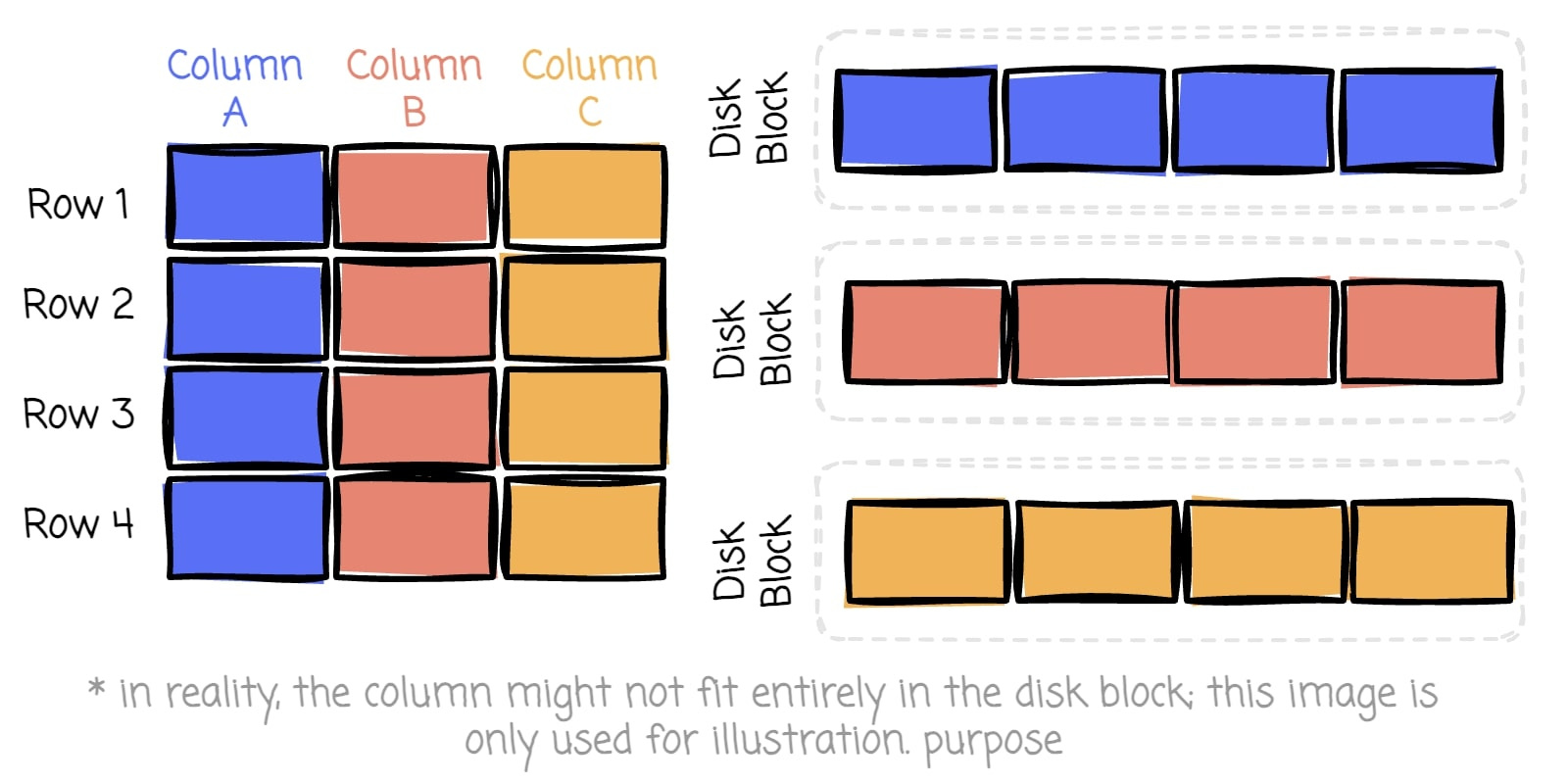
👉 Side note: Worth noting that this also makes vectorized execution way more efficient. Engines like DuckDB and ClickHouse thrive on this layout because CPUs can do SIMD tricks when data types are aligned.
However, storing data in a columnar format has some downsides. The record write or update operation requires touching multiple column segments, resulting in numerous I/O operations. This can significantly slow the write performance, especially when dealing with high-throughput writes.
When queries involve multiple columns, the database system must reconstruct the records from separate columns. The cost of this reconstruction increases with the number of columns involved in the query.
👉 Side note: And it gets worse when people naively try to "stream" into Parquet. Parquet is optimized for batch, not row-at-a-time ingestion. If you're writing from Kafka, buffer into batches before flushing.
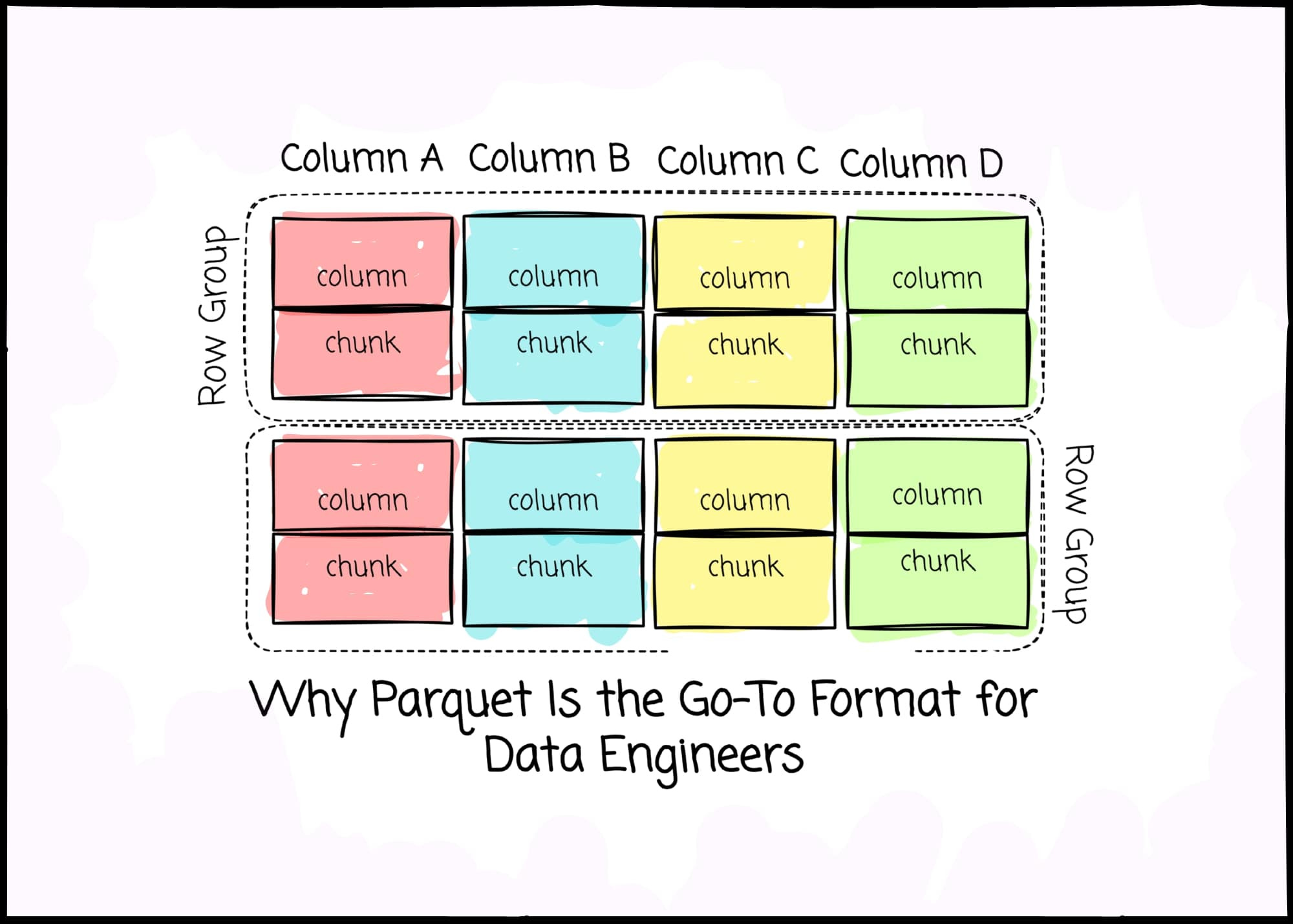
The hybrid format combines the best of both worlds. The format groups data into "row groups," each containing a subset of rows (aka horizontal partition). Within each row group, data for each column is called a “column chunk" (aka vertical partition).
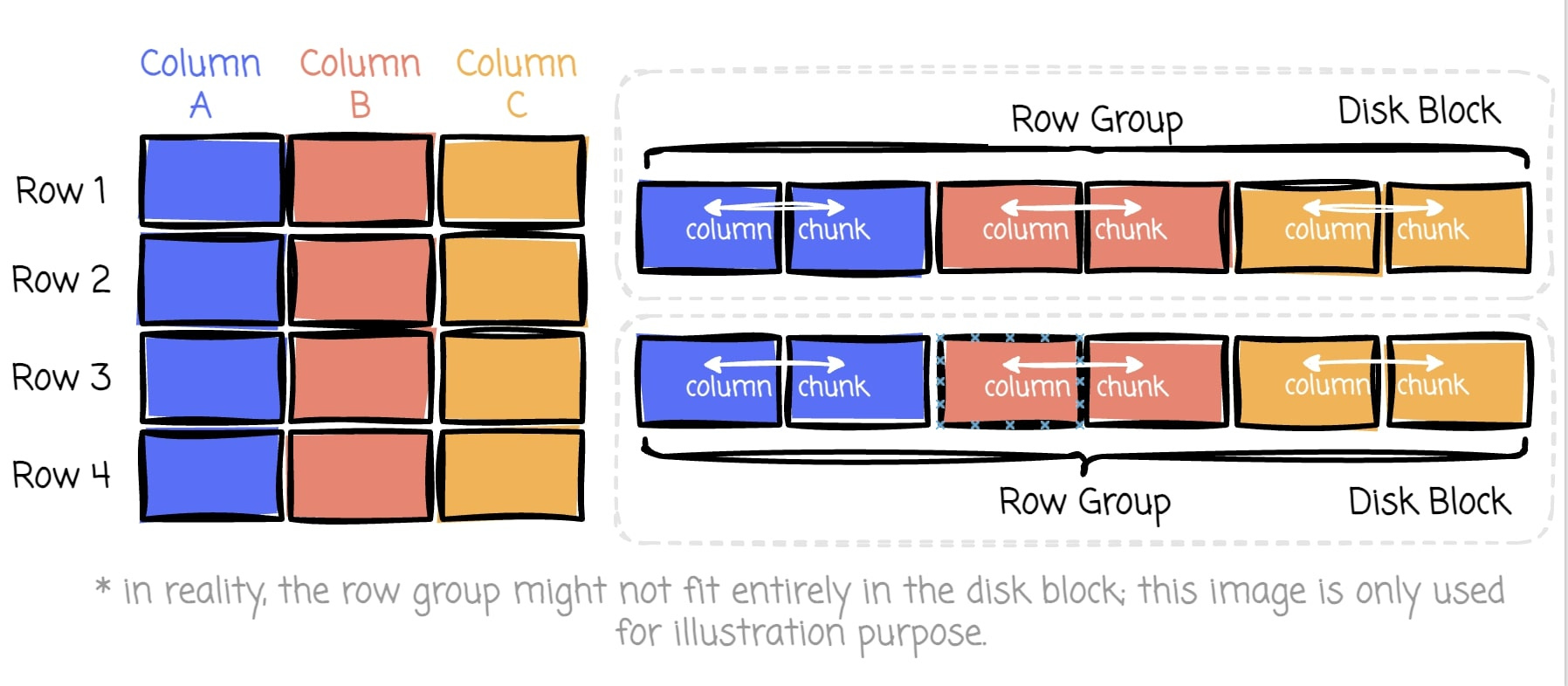
In the row group, these chunks are guaranteed to be stored contiguously on disk. I used to think Parquet was purely a columnar format, and I’m sure many of you might think the same. To describe it more precisely, Parquet organizes data in a hybrid format.
We will delve into the Parquet file structure in the following section.
Terminologies and metadata
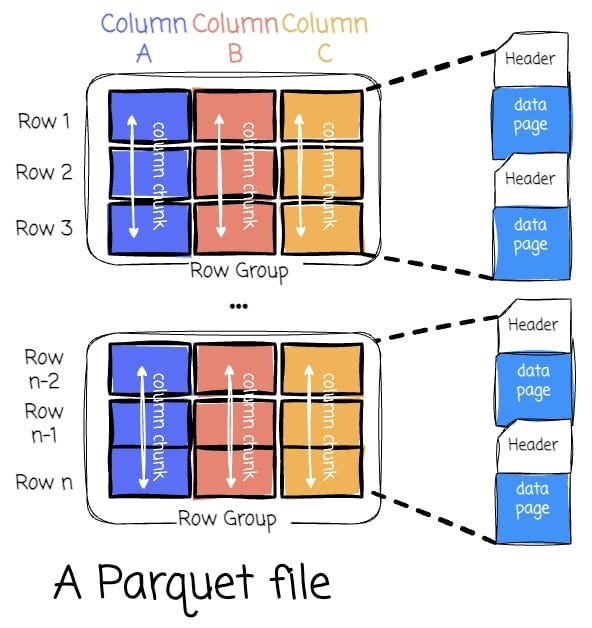
A Parquet file is composed of:
Row Groups: Each row group contains a subset of the rows in the dataset. Data is organized into columns within each row group, each stored in a column chunk.
Column Chunk: A chunk is the data for a particular column in the row group. Column chunk is further divided into pages.
Pages: A page is the smallest data unit in Parquet. There are several types of pages, including data pages (actual data), dictionary pages (dictionary-encoded values), and index pages (used for faster data lookup).
Parquet is a self-described file format that contains all the information needed for the application that consumes the file. This allows the software to understand and process the file without requiring external information. Thus, the metadata is the crucial part of Parquet:
Magic number: The magic number is a specific sequence of bytes (
PAR1) located at the beginning and end of the file. It is used to verify whether it is a valid Parquet file.FileMetadata: Parquet stores FileMetadata in the footer of the file. This metadata provides information like the number of rows, data schema, and row group metadata. Each row group metadata contains information about its column chunks (ColumnMetadata), such as the encoding and compression scheme, the size, the page offset, the min/max value of the column chunk, etc. The application can use information in this metadata to prune unnecessary data.
PageHeader: The page header metadata is stored with the page data and includes information such as value, definition, and repetition encoding. Parquet also stores definition and repetition levels to handle nested data. The application uses the header to read and decode the data.
In the following section, I will deliver my understanding of the process of Parquet writing and reading data. I wrote a simple Python program to write a small Pandas dataframe to a Parquet file and read this file back.
How is data written in the Parquet format?
Here’s the overview process when writing a dataset into a Parquet file:
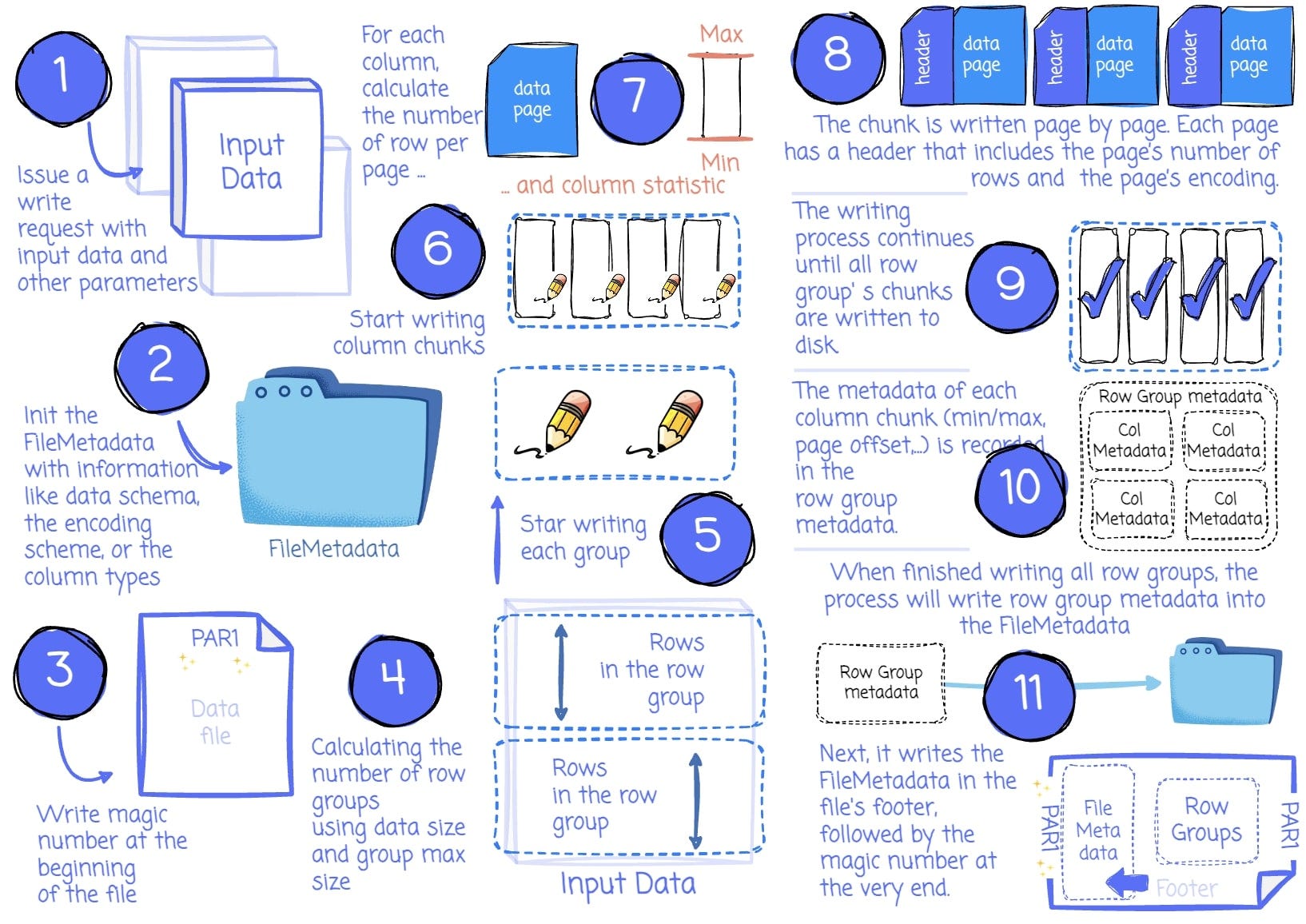
The application issues a written request with parameters like the data, the compression and encoding scheme for each column (optional), the file scheme (write to one or multiple files), etc.
The Parquet Writer first collects information, such as the data schema, the null appearance, the encoding scheme, and all the column types recorded in FileMetadata.
The Writer writes the magic number at the beginning of the file.
Then, it calculates the number of row groups based on the row group’s max size (configurable) and the data’s size. This step also determines which subset of data belongs to which row group.
For each row group, it iterates through the column list to write each column chunk for the row group. This step will use the compression scheme specified by the user (the default is none) to compress the data when writing the chunks.
The chunk writing process begins by calculating the number of rows per page using the max page size and the chunk size. Next, it will try to calculate the column's min/max statistic. (This calculation is only applied to columns with a measurable type, such as integer or float.)
Then, the column chunk is written page by page sequentially. Each page has a header that includes the page’s number of rows, the page’s encoding for data, repetition, and definition. The dictionary page is stored with its header before the data page if dictionary encoding is used.
After writing all the pages for the column chunk, the Parquet Writer constructs the metadata for that chunk, which includes information like the column's min/max, the uncompressed/compressed size, the first data page offset, and the first dictionary page offset.
The column chunk writing process continues until all columns in the row group are written to disk contiguously. The metadata for each column chunk is recorded in the row group metadata.
After writing all the row groups, all row groups’ metadata is recorded in the FileMetadata.
The FileMetadata is written to the footer.
The process finishes by writing the magic number at the end of the file.
How about the reading process?
Here’s the overview process when reading a Parquet file:
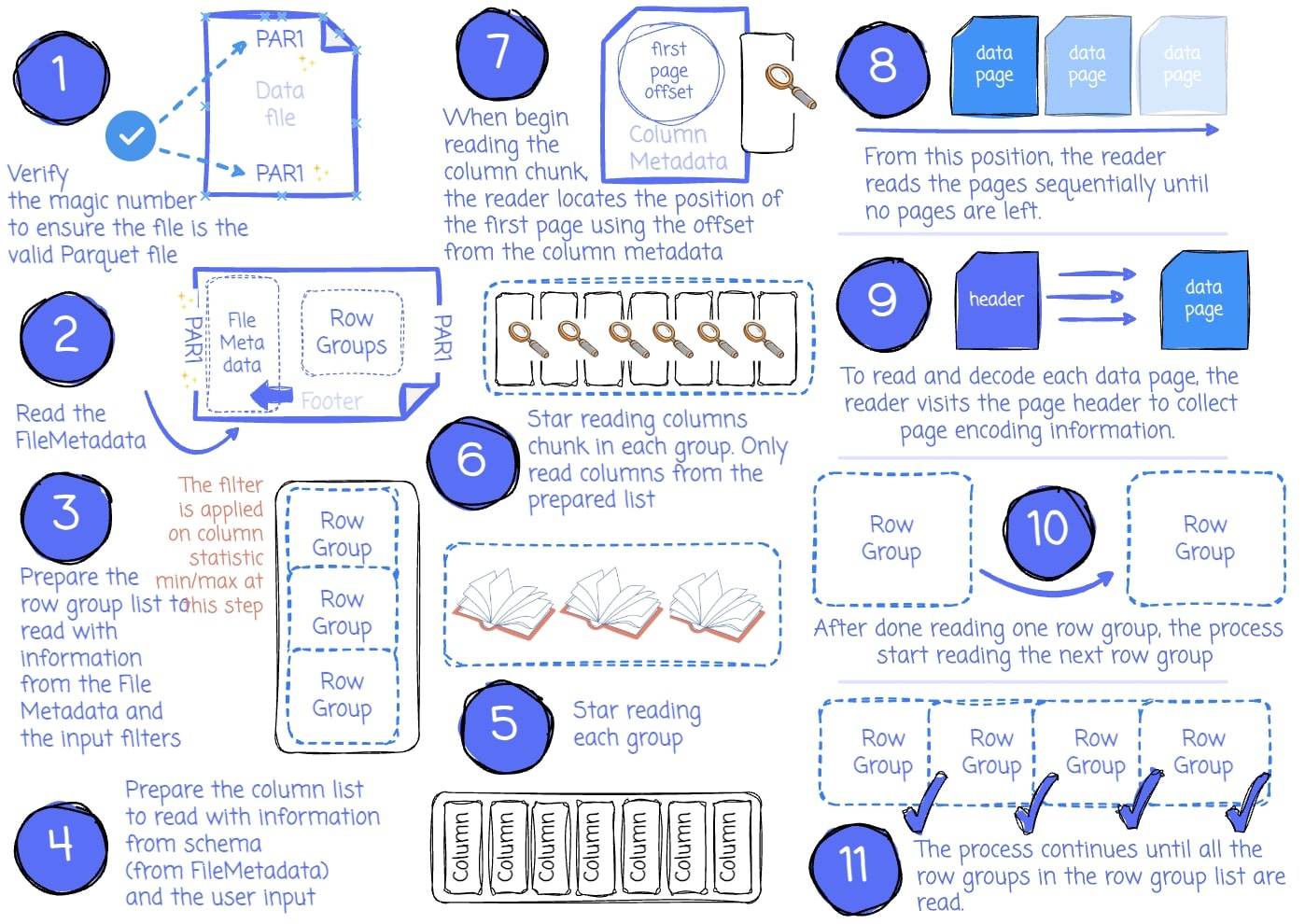
The application issues a read request with parameters such as the input file, filters to limit the number of read row groups, the set of desired columns, etc.
If the application requires verification that it’s reading a valid Parquet file, the reader will check if there is a magic number at the beginning and end of the file by seeking the first and last four bytes.
It then tries to read the FileMetadata from the footer. It extracts information for later use, such as the file schema and the row group metadata.
If filters are specified, they will limit the scanned row groups by iterating over every row group and checking the filters against each chunk’s statistics. If it satisfies the filters, this row group is appended to the list, which is later used to read.
The reader defines the column list to read. If the application specifies a subset of columns it wants to read, the list only contains these columns.
The next step is reading the row groups. The reader will iterate through the row group list and read each row group.
The reader will read the column chunks for each row group based on the column list. It used ColumnMetadata to read the chunk.
When reading the column chunk for the first time, the reader locates the position of the first data page (or dictionary page if dictionary encoding is used) using the first page offset in the column metadata. From this position, the reader reads the pages sequentially until no pages are left.
To determine whether any data remains, the reader tracks the current number of read rows and compares it to the chunk’s total number of rows. If the two numbers are equal, the reader has read all the chunk data.
To read and decode each data page, the reader visits the page header to collect information like the value encoding, the definition, and the repetition level encoding.
After reading all the row groups’ column chunks, the reader moves to read the following row groups.
The process continues until all the row groups in the row group list are read.
Observation
My observation along the way
Multi-files
The application can specify the writing process to output the dataset into multiple files or even specify the partition criteria so that the process can organize the Parquet output files into Hive partition folders. For example, all data on 2024-08-01 is stored in the folder date=2024-08-01, and all data on 2024-08-02 is stored in the folder date=2024-08-02.
Parallelism
Because the Parquet file can be stored in multiple files, the application can read them simultaneously.
In addition, a single Parquet file is partitioned horizontally (row groups) and vertically (column chunks), which allows the application to read data in parallel at the row group or column level.
Encoding
Data from a column chunk in Parquet is stored together. This helps Parquet encode the data more efficiently because data in the same column tends to be more homogeneous and repetitive.
Parquet leverages dictionary and run-length encoding (RLE) techniques to significantly reduce storage space. After dictionary encoding, the data is further run-length encoded in Parquet.

Dictionary encoding replaces repeated values with shorter, unique keys, reducing redundancy and improving compression. As far as I know, dictionary encoding is implemented by default in Parquet. It will be applied if the data satisfies a predefined condition (such as the number of distinct values).
RLE, on the other hand, compresses consecutive identical values by storing the value once along with its repetition count. These methods minimize the amount of data stored and optimize read performance by reducing the amount of data that needs to be scanned.
👉 Side note: A practical tip here — don’t just assume RLE will kick in. Your data needs to be sorted or clustered to get the full benefit. This is why bucketing and sorting before writing Parquet matters.
OLAP workload
The ability to filter row groups using statistics and choose only the columns needed to read can significantly benefit the analytic workload. Giving the following query:

With the following Parquet layout, we only need to read row groups 1 and 2, focusing on columns A and B in each row group rather than reading all columns.
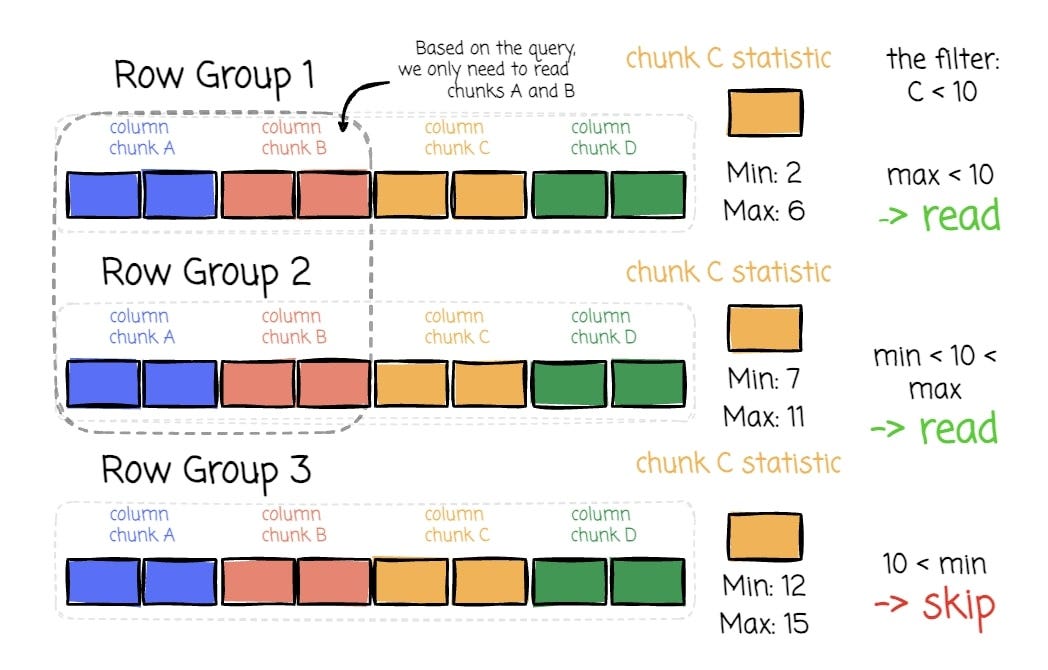
👉 Side note: And this is why BigQuery, Snowflake, Athena — basically every lakehouse — loves Parquet. Predicate pushdown, column projection, and parallelism make it the format for ad-hoc slice-and-dice workloads.
Parquet Optimization & Best Practices
Parquet, like with most powerful tools in Data Engineering, is less about what it can do and more about how you use it. A few good practices can keep you from shooting yourself in the foot.
1. Leverage Predicate Pushdown
Predicate pushdown lets query engines filter data at the file or row group level, cutting down the amount of data scanned.
Parquet stores min/max statistics for each column in a row group, which enables efficient data skipping.
Make sure your processing tools (Spark, DuckDB, whatever) are configured to take advantage of this. Write queries that actually use those min/max stats — don’t force full scans with overly dynamic filters.
2. Choosing the Right Compression Codec
Parquet supports multiple compression options, each with trade-offs:
Snappy: Fast compression/decompression with moderate compression ratio. Great for analytics where speed matters more than storage.
Gzip: Higher compression ratio but slower. Use when saving space is more critical than read speed.
Zstandard (ZSTD): Excellent balance between speed and ratio, with tuning knobs if you're brave.
Choose a compression codec that aligns with your performance and storage requirements. Test different codecs to determine the best fit for your workload.
3. Avoid Small Files
Too many small files? Welcome to metadata hell. You’ll pay in I/O and memory.
Each file brings overhead: headers, footers, metadata, and file system ops.
Merge small files into larger chunks — ideally 128MB to 1GB. Use tools like Apache Spark or Apache Hudi for file compaction.
4. Pick the Right Row Group Size
As we’ve seen, row groups are the fundamental units of work in Parquet files. Choosing the right size is crucial:
Larger row groups (128MB to 512MB) reduce metadata overhead and improve read performance by minimizing I/O operations.
Smaller row groups offer better parallelism and finer-grained data skipping but may increase metadata and result in slower queries.
As a best practice, aim for a row group size that balances I/O efficiency and query parallelism, typically between 128MB and 512MB, depending on your system's memory and processing capabilities.
5. Optimize Encoding Strategies
Parquet supports multiple encoding techniques to reduce file size and improve performance:
Dictionary Encoding: Great for low-cardinality strings (like gender, country codes, etc)
Run-Length Encoding (RLE): Perfect for repeated values (think boolean flags or sorted data).
Delta Encoding: Best for slowly incrementing numbers (like timestamps).
The advice is to let your engine pick the default, but override it if you know better. And for the love of columns — sort first to help RLE kick in.
6. Sort Data for Faster Queries
Sorted data = faster filters and better compression.
Sort by columns frequently used in WHERE clauses or range queries. It helps predicate pushdown work more effectively and makes encodings more efficient.
Pre-sort before writing to Parquet — especially if you’re doing batch writes via Spark, Pandas, or Dask.
7. Use Transactional Table Formats
Need schema evolution, ACID semantics, or time travel? Don’t force it on raw Parquet.
Use formats like Apache Iceberg, Delta Lake, or Apache Hudi — they wrap Parquet with rich metadata and proper versioning.
If your use case involves frequent updates, versioning, or concurrent writers, these formats are your friends.
Outro
Parquet isn’t glamorous. It’s not the latest AI model or some trendy stream processor. It’s a file format. A box for your bytes. And that’s exactly why people underestimate it — until their queries get slow, their storage bill explodes, or their “data lake” turns into a swamp.
Most pipelines suck not because the code is bad, but because the files are. Wrong row group size? Poor partitioning? No compression? Now you have 5x slower jobs, and no one knows why.
So yeah, maybe you don’t need to know every byte offset in the footer. But you do need to care. Because once you start thinking about layout, not just logic, you stop duct-taping pipelines and start building systems.
That’s how you stop being just another engineer gluing together APIs — and start being the one who actually makes things fast.

References
[1] Anastassia Ailamaki, David J. DeWitt, Mark D. Hill, Marios Skounakis, Weaving Relations for Cache Performance
[3] Wes McKinney, Extreme IO performance with parallel Apache Parquet in Python (2017)
[4] Michael Berk, Demystifying the Parquet File Format (2022)
 | A guest post by
|